Running a Home AI Server With Open WebUI and AWS Bedrock
Update March 29, 2026: Things have changed, out there, to say the least. I still use Open WebUI regularly to chat with various models. I rarely use the Bedrock gateway anymore in favor of direct provider API connections.
The repo is diverging from this post as I refine the configuration and automate parts of it. I changed the remote access reverse proxy model from nginx/self-signed certs to an easier Tailscale/Caddy setup–easier if you use Tailscale, that is. I'll leave the original manual nginx setup here.
1. Introduction
My current LLM usage boils down to:
- At work: ChatGPT for virtual pair programming, search, prototypes; JetBrains Full Line code completion for autocomplete
- At home: On again/off again Claude.ai subscription (same use cases as ChatGPT above)
This is a solid base to get stuff done and keep an eye on the LLM development horse race between two commercial players, but of course there are other providers releasing models with different capabilities all the time, and, out of professional and personal curiosity, it'd be nice to have an easy way to compare them.
And I'd like to make chat available to others in my household for exploration and learning, ideally with leading models, a nice UI, fast interactive performance, and low to no cost, i.e. no server cost and pay-as-you-go API cost.
Llamafile and Ollama are fine for kicking the tires on open weight models locally, but they're limited to system memory, slow on my hardware, and don't meet the UI bar. Simon Willison's llm is a superb Swiss army knife, but the command line is the not UI treasure I seek here. Poe's $20/mo family plan checks the multi-user, multiple models boxes, but if I recall correctly there are rate limit and feature limitations at that price point.
Thought: AWS Bedrock offers Llama, Claude, and other models as "foundation models" running on their GPUs with pay-as-you-go pricing. There should be a way to connect a UI to all the models in my AWS account.
And there is: Open WebUI and an API adapter meet these needs nicely.
I'll describe the components and then describe a docker compose setup to run them locally.

2. Frontend
Open WebUI is a strikingly good open source (BSD-3) web app. Like, wow, well done, folks. I assume it started it as an open source clone of ChatGPT, but it's more than that. It has tons of features, all well designed.
- Connects to local Ollama out of the box
- Connect to any OpenAI API-compatible endpoint
- Displays generated code and web apps similar to Claude Artifacts
- Runs generated Python code like ChatGPT Code Interpreter but sandboxed in the browser
- It's easy to rerun a prompt with a different model and compare output
- If you want, you can configure N models to run by default and compare side-by-side all the time
- The design is responsive and works great on mobile
- The admin UI presents all the controls I would want and then some. There's a whole area of custom tool integration and workflows that I haven't touched.
It's a good app.
Open WebUI is easy to install with docker and access over HTTP on localhost. Only because SSL is a prerequisite to add a progressive web app to the home screen on iOS, I also run nginx as a reverse proxy with self-generated SSL certs.
3. Backend
AWS provides models and will happily and run inference for you on their hardware. The problem is Open WebUI expects an openai-compatible endpoint, and AWS API is not that. My current solution uses two open source API adapters (one or the other may suit your needs). I also have Ollama running locally and connect the UI to that, but I don't use it much.
One cool thing is once you have access to Bedrock through an openai-compatible endpoint, you can point other tools to it, including editor plugins like gptel or continue.dev, and they can access the same models as Open WebUI.
Chat models: Bedrock Access Gateway
Bedrock Access Gateway exists expressly to wrap an openai-compatible endpoint around the AWS Bedrock API. Connecting Open WebUI to this endpoint exposes all Bedrock models enabled in your AWS account/region as chat models in the app.
Embedding model: LiteLLM
If you upload documents in chat, Open WebUI uses an embedding model to process the files. By default, it uses a smallish local model called SentenceTransformers. If you have a gaming GPU or Apple Silicon, you can leave the defaults and skip all the embedding setup.
My GPU isn't up to it, so I offload embedding to AWS. Again, we need an API adapter. In theory Bedrock Access Gateway supports embedding, but I got stuck configuring it to use AWS's Titan embedding model.
I ended up solving the problem quickly with LiteLLM, another open source API adapter. LiteLLM supports many other chat model providers and has a long list of its own features–technically it's more than sufficient for all OpenWebUI's model needs. The downside is that for chat, the configuration is not quite dialed for the "expose all my Bedrock models" use case. In wildcard mode, it floods the models list in the UI with AWS models I don't have enabled.
4. Setup
This all sounds like a lot, but if you're comfortable with docker and AWS, it's fairly straightforward to set up. I've included all the configuration files needed to run the servers in the post for reference. They are also available at https://github.com/shoover/home-ai-server.
Requirements review:
- No monthly server cost
- Pay-as-you-go model API cost
- App available on LAN only
- API available on localhost only
- One-time setup/config is ok if not too painful
- Start up with one command
- Restart on reboot
Create compose file
I use docker compose to configure and run all the servers. Save this as
compose.yaml. The rest of the files should be saved in the same directory.
services:
# Expose the app on the LAN via https. If you don't need SSL, you can remove
# this and connect to open-webui via http://localhost:3000.
nginx:
image: nginx:latest
ports:
- "3443:443"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
- ./certs/cert.pem:/etc/nginx/cert.pem:ro
- ./certs/key.pem:/etc/nginx/key.pem:ro
restart: unless-stopped
# Standard open-webui (without embedded ollama). All it needs is a volume to
# store the database.
open-webui:
image: ghcr.io/open-webui/open-webui:main
ports:
# Expose the app on localhost via plain HTTP for debugging. Change to
# 0.0.0.0 to expose plain HTTP on the LAN.
- "127.0.0.1:3000:8080"
volumes:
- open-webui:/app/backend/data
restart: unless-stopped
# Bedrock Access Gateway serves Bedrock chat models
bedrock-gateway:
build:
context: ./bedrock-access-gateway/src
dockerfile: ./Dockerfile_ecs
ports:
# Expose the API on localhost for testing and local use. Don't open to the
# web or LAN without overriding the default access token.
- "127.0.0.1:4000:80"
environment:
# AWS config is loaded from .env
AWS_ACCESS_KEY_ID: "${OPENWEBUI_AWS_ACCESS_KEY_ID}"
AWS_SECRET_ACCESS_KEY: "${OPENWEBUI_AWS_SECRET_ACCESS_KEY}"
AWS_REGION: "${OPENWEBUI_AWS_REGION}"
DEBUG: false
restart: unless-stopped
# LiteLLM serves the Bedrock embedding model
litellm:
image: ghcr.io/berriai/litellm:main-latest
command: ["--port", "4100", "--config", "/app/config.yaml"] #, "--detailed_debug"]
ports:
# Expose the API on localhost for testing and local use. Don't open to the
# web or LAN without overriding the hardcoded access token.
- "127.0.0.1:4100:80"
volumes:
- ./litellm.yaml:/app/config.yaml:ro
environment:
AWS_ACCESS_KEY_ID: "${OPENWEBUI_AWS_ACCESS_KEY_ID}"
AWS_SECRET_ACCESS_KEY: "${OPENWEBUI_AWS_SECRET_ACCESS_KEY}"
AWS_REGION_NAME: "${OPENWEBUI_AWS_REGION}"
restart: unless-stopped
volumes:
open-webui:
Create AWS IAM resources
Create an IAM user, role, and policy to allow the API adapters to connect to AWS Bedrock.
Here's the policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
"bedrock:ListFoundationModels",
"bedrock:ListInferenceProfiles"
],
"Resource": "*"
}
]
}
You can create the resources in the console if you prefer. I used the script below (next time I'd create a CloudFormation template).
Save all three OPENWEBUI_AWS_* variables to .env in the same directory as the
compose file.
#!/bin/bash ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) AWS_REGION=us-east-2 # Create policy, user, attach policy, create keys and output in .env format aws iam create-policy \ --policy-name open-webui-invoke \ --policy-document file://open-webui-invoke-policy.json aws iam create-user --user-name open-webui-local-server aws iam attach-user-policy \ --user-name open-webui-local-server \ --policy-arn arn:aws:iam::${ACCOUNT_ID}:policy/open-webui-invoke aws iam create-access-key \ --user-name open-webui-local-server \ --query 'AccessKey.[AccessKeyId,SecretAccessKey]' \ --output text | awk '{print "OPENWEBUI_AWS_ACCESS_KEY_ID=" $1 "\nOPENWEBUI_AWS_SECRET_ACCESS_KEY=" $2}' print "OPENWEBUI_AWS_REGION=${AWS_REGION}"
Enable Bedrock foundation models
While you're in the AWS console, request access to all the models you want to use. AWS usually responds within a few minutes, and then you can try them out in the console.
us-east-1 has the most options. I'm closest to us-east-2, so I use that region.
Configure litellm
litellm.yaml:
model_list:
- model_name: amazon-titan-embeddings
litellm_params:
model: "bedrock/amazon.titan-embed-text-v2:0"
general_settings:
# Note the hardcoded API key. Firewall the litellm server port accordingly.
master_key: my-litellm
Check out Bedrock Access Gateway
git clone https://github.com/aws-samples/bedrock-access-gateway.git
Optional: Generate certs and configure nginx
Nginx and SSL are needed only if you need encrypted transport and want to add
the progressive web app to your home screen. I self-signed certs with my PC's
hostname using mkcert on Windows. You can also use openssl or skip this and
use plain HTTP.
nginx.conf:
events {
worker_connections 32;
}
http {
server {
listen 443 ssl;
ssl_certificate /etc/nginx/cert.pem;
ssl_certificate_key /etc/nginx/key.pem;
# Increase size from default for document/image uploads.
client_max_body_size 8M;
location / {
proxy_pass http://open-webui:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
# Websocket support
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
}
Start the services
docker compose up --detach --pull always --build
Set up Open WebUI
After several seconds, the containers should all be running. Navigate to http://localhost:3000 to access the app.
You only need to do a couple things to get started. First, you'll be prompted to create an admin account. You can start chatting with the default settings, assuming you have Ollama running.
To set up Bedrock models, go to the admin settings and create connections to your chat and embedding models.
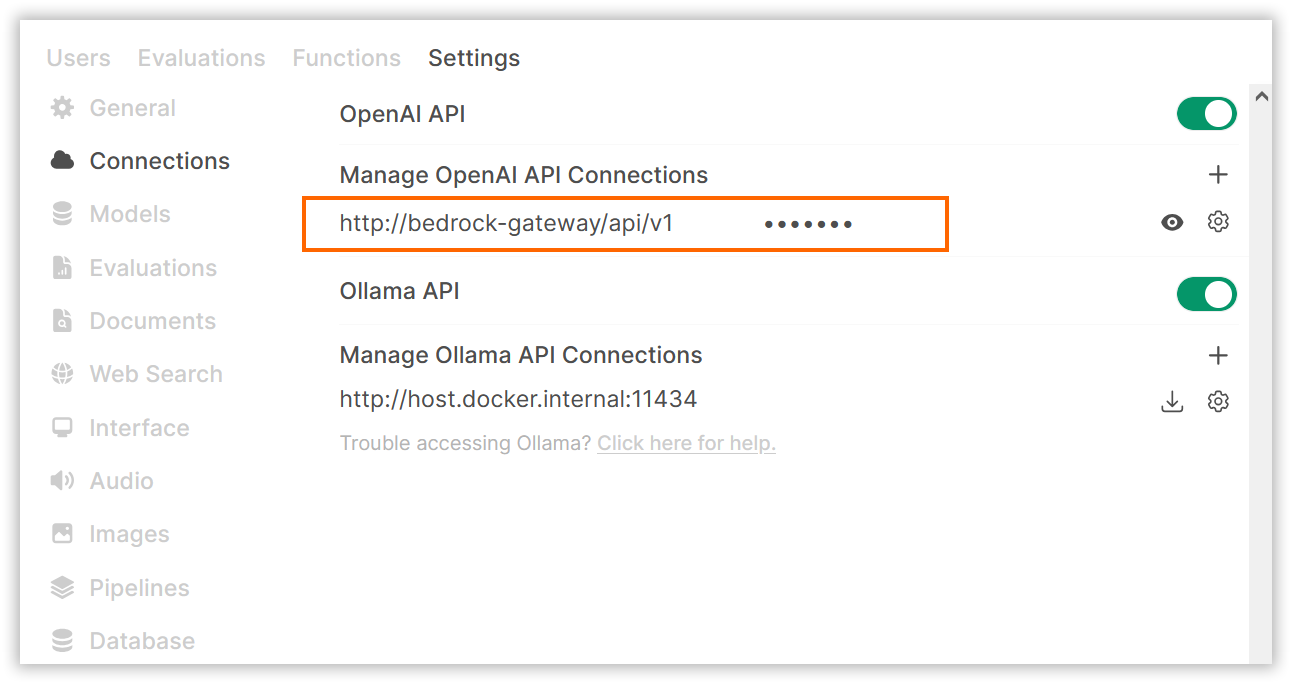
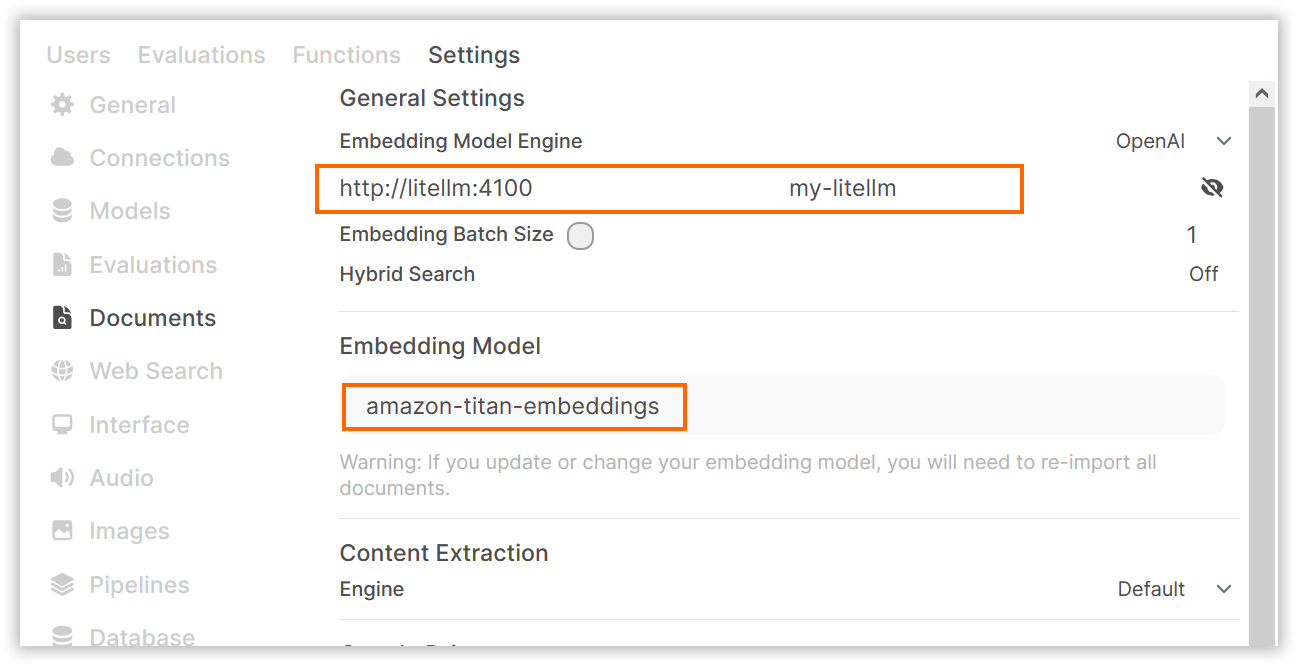
Now you can go to the home page, select any Bedrock model, and start chatting.
You can add users through the admin panel anytime.
Happy exploring.
5. Maintenance
The compose setup is mostly set and forget. When there is an Open WebUI update available, it will nag in-app. Rerun the start command to pull the latest. As long as you don't delete the containers, chat history and settings will be preserved in the docker volume across restarts. (There's an easy way to automate this; I'll get around to it.)
You may want to export model and UI settings after initial setup. Go to Settings, Database, Export Config to JSON File. This downloads a file you can back up. (I wouldn't be surprised if there's a way to mount a docker volume and sync this file between docker and the host automatically, but I haven't checked.)
I don't bother backing up the chat history database, but there's a button in the same admin page.
6. Conclusion
I'm happy with this setup. Docker compose is a nice platform to deploy home servers. It's nice running multiple models and comparing takes on questions. I set the default to Claude 3.5 Sonnet, but I'll often compare with Llama 3.3, Nova Pro, and new smaller models as they're released. I cancelled my Claude.ai subscription and use Open WebUI about 50/50 with Claude.ai (Free). Household members have accounts and get a kick out of playing around with it. My AWS inference bill is running $2/month.
